Pranav Reddy
Avoiding the steamroller of foundation model capability
The most common refrain from the large labs in response to founders concerned about whether the next model release will bulldoze their product is to “build a product where you're excited instead of scared when a new model comes out.” This view often feels incomplete to me because if the labs achieve the grand goal of AGI, then models will be able to do everything we can — at which point, it's pretty hard to identify what there is left to build. every startup's level of excitement at new model release depends on how much better the new model is than the old one.
A reframing that I think more accurately conveys the message is to build a company where you're excited when the learning efficiency [1] improves by about an order of magnitude. I use “learning efficiency” to roughly refer to the number of demonstrations required to teach a model a new skill. put another way, if i'd like to teach the model to reason in a domain for which data doesn't exist today, how many examples does the model need to see before it performs passably well to be commercially useful. a quick illustration below -- by "quality of business" I roughly mean what fraction of value an independent company in that market would capture.
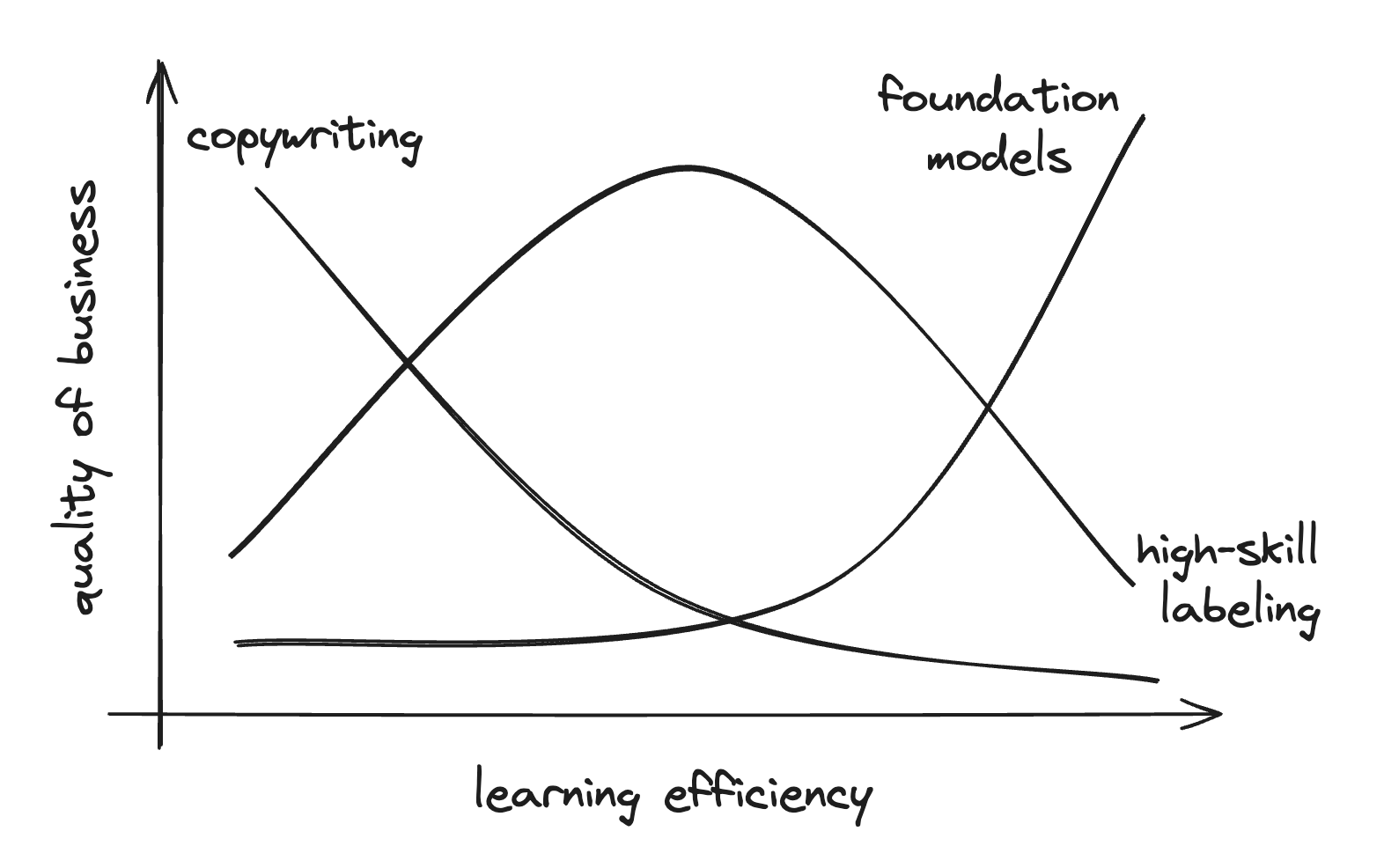
Marketing copy-writing companies founded in 2020 (e.g. Copy, Jasper) were the first set of rapidly growing companies built on top of model APIs. The original set of features they built were series of prompt templates that cajoled models into working better for common usage patterns like “technical blog post” or “product comparison.” When the next generation of model interfaces (e.g. ChatGPT, Claude) and APIs were launched, this specification layer became redundant as models became much more efficient at replicating style with only a few examples presented in context.
For customer support agents, the primary customer concerns are agents having sufficient context, matching brand voice, and taking actions through internal systems. These businesses clearly benefit from significantly improved learning efficiency. models today are still not effective at adjusting their behavior to shifting customer behavior and business objectives or at matching tone over multi-turn conversations -- simply asking Nike's model not to advertise Addidas' shoes isn't enough to convince it not to. As some enthusiastic researchers will argue, in the limit, models will do it all — they'll write their own integrations into customer systems, devise their own A/B tests on quality of messaging. but we remain at least a couple orders of magnitude of learning efficiency away from models being able to do that autonomously. In that time, there's probably still plenty of opportunity to build a really great business.
As a more nuanced example, consider high skill human data as a business, e.g. paying for software engineers to identify bugs in code or lawyers to red line legal documents. Five years ago, when models were extremely inefficient at learning from examples, this business was terrible because the value proposition for the customers of human data was also terrible — the amount of money you'd have to spend to generate enough examples to train a model of any utility was likely in the trillions of dollars of spend (or even impossible). At the other extreme, if models get many many times better at learning efficiently, there likely isn't a very good high skill business either! If I only need a few lawyers to generate enough data to train a high quality legal model, then an independent labeling company is unlikely to solve enough pain for any customer to build a great business. Coincidentally, the modern data regime, where models can learn from data but they still need a substantial number of examples, is a pretty ideal setting!
Instead of asking “am I excited when a new model comes out?,” a better question might be “am I excited for models to get a bit more efficient at learning?”
Notes:
[1] "Learning efficiency" is similar to but not the same as "sample efficiency". The latter is a technical term used to denote how many examples a model needs to learn a new behavior/pattern in training. :earning efficiency, as described here, is about how many examples a deployed model needs to adapt to a specific new task or context - essentially its few-shot or in-context learning capabilities. It's a business metric about practical application.