Pranav Reddy
An index for intelligence
Search & language model training have pretty similar core mechanics — they glom up information from around the web and use them to better understand the structure of language. It's no surprise then that new chatgpt search integration Open AI just released is pretty good! Compared to SearchGPT, it's noticeably faster, demonstrates improved query understanding, and even has some coverage of “one-boxen” [1] for popular queries. At the same time, this Open AI release helps more clearly demonstrate that while language models have made substantial advances in query understanding, the lack of a true search index still seriously hurts search quality.
Traditionally, search engines are composed of four core elements[2]:
- the interface, which is everything from the information organization on screen to the search entry point [3]
- query understanding, which takes the short (typically 2-3 word) query string and “expands” it into a richer understanding, via synonymy, stemming and, more recently, embeddings
- retrieval & ranking, which uses this expanded query to retrieve potentially relevant pages and then scores & orders them prior to presentation
- the index, built by crawling & recrawling billions of pages, which contains a record of every webpage the search engine has ever seen (in addition to a variety of enriched information, like past user behavior on that page, backlinks, etc.)
Search in ChatGPT is a remarkably good replacement for query understanding and ranking, which alone, is no small feat — thousands of engineers at google have worked for more than a couple decades on building efficient scoring algorithms, aided by the data of billions of queries a day. However, these improvements don't replace the need for an index, and ChatGPT's responses suffer as a result of the limited index it has access to. A couple examples, taken from my recent search history:
A query i've made now dozens of times over the last year is “snow stock” to check the most recent snowflake stock price. ChatGPT gives me a verbose answer, stating the price at close was $118.99 and provides some analysis of what analysts have said. I'd argue the google response with a stock ticker is much more efficient, but the biggest issue with this answer is that it's just wrong! The source chatgpt cites shows the correct close, and some basic sleuthing suggests chatgpt is citing the stock price from the previous day. To hazard a guess, my bet is the last crawl snapshot of the page was at ~6PM ET, which counts as Oct 31st in GMT (standard timezone) but actually reflects the price on Oct 30th.

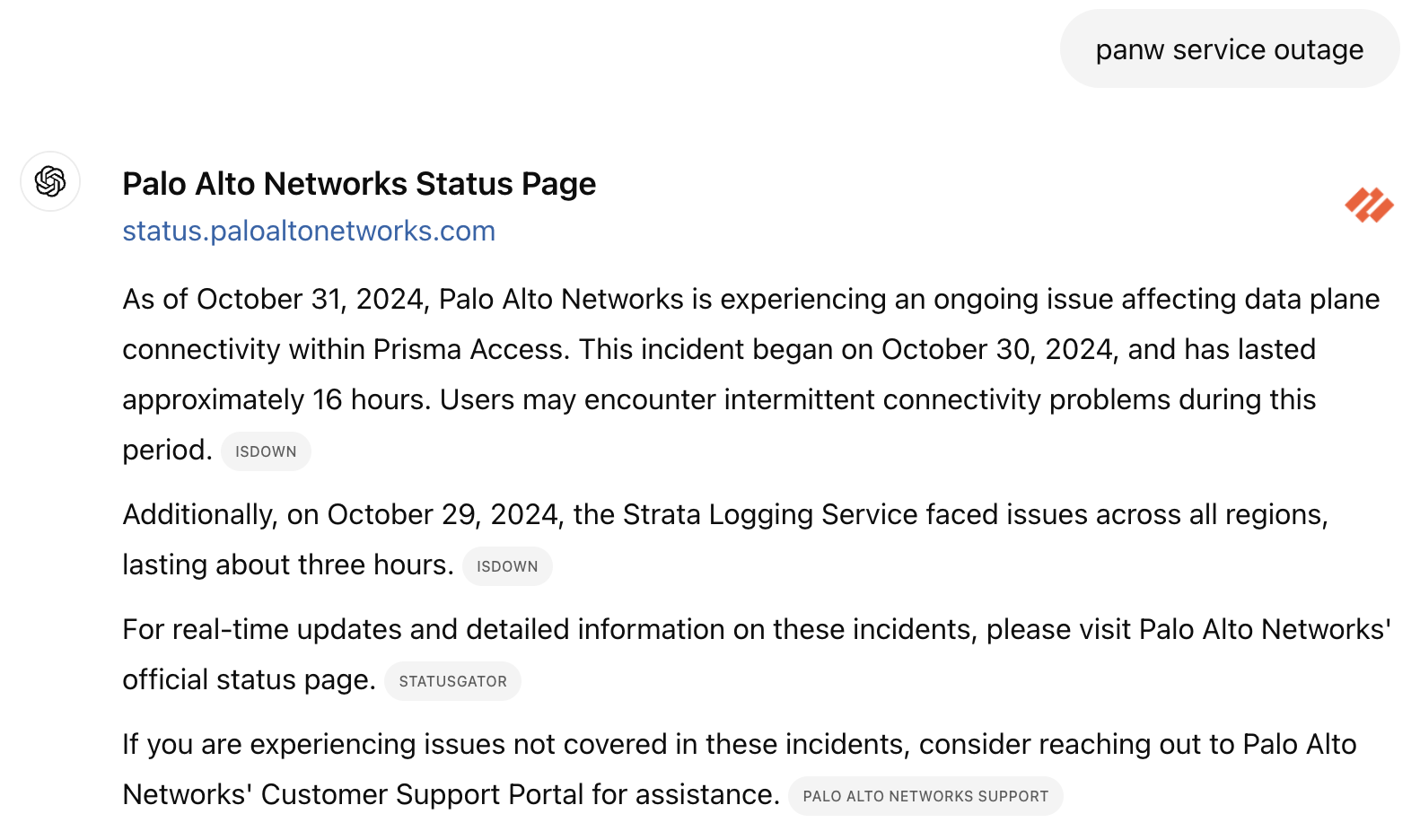
It's a perfectly understandable mistake, and this specific instantiation is easily resolvable with better data feeds, but this query represents one of a pattern of mistakes that ChatGPT tends to make where the model semantically understands the query but lacks an up-to-date search index. The query “panw service outage” demonstrates a different variant of this problem, where GhatGPT hallucinates an ongoing service outage despite the cited source demonstrating that the most recent service incident being from more than a month ago. The model correctly identified the status page as the right source, but either has an outdated snapshot in index & manufactures an incident that doesn't exist or can't translate the query intent to the appropriate part of the page.
One last example — a couple weeks ago, I saw a comment on reddit saying “investigate 3/11,” a reference I hadn't heard of to an eric andre skit. While google captures the intent, demonstrated through video titles and a series of reddit posts from “r/outoftheloop,” ChatGPT instead provides a list of historical events that occurred on the day. Digging a little deeper into the list of sources provided, it's clear that chatgpt is missing coverage on a bunch of sites that explain the meme (e.g. youtube/video results, reddit, fandom, etc.) and lacks the historical query data to understand that this query is likely looking for an explanation.

That being said, I'm genuinely surprised and impressed by how often the model does accurately capture my intent. “chase virtual credit card” correctly informs me that Chase doesn't provide virtual credit cards, whereas Google gives me a list of links that erroneously suggest ways I might be able to get one. “apple macbook update” incorporates data from news sites from less than a couple hours ago (though, notably, the query “apple macbook” provides a history of the macbook product line rather than news on the most recent update). With some bias from years of having worked on more traditional search, it's hard to imagine how chatgpt could be a like-for-like replacement for google without building an index themselves.
Notes:
[1] the punny name for the herd of one-box answers at the top of a search result page. search for "warriors game" or "thai food near me" for some examples.
[2] in my time at neeva, the search engine startup i worked at before, i helped build chunks of each of these systems, with the least time on interface and the most on some mix of ranking and indexing
[3] it's hard to overstate the importance of the entry point for the spread of a search engine. the fact that the address bar of almost every browsers directing to google is arguably the single largest advantage google has. probably worthy of its own article